How to Read a Text File Seaborn
I've heard a lot of analysts/data scientists proverb they spend well-nigh of their time cleaning information. You ' ve probably seen a lot of tutorials to make clean your dataset but you probably know that already: it volition never be 100% clean and y'all have to sympathize that point before standing to read this article. And then I'll be honest with y'all: I won't give you the magic recipe to get rid of all the data bug you might accept with your dataset. The cleaning rules depend on the domain you are working on and the context of your projection. The examples of this article come from my own experience with data manipulation in the real globe.
I've dealt with all the bug/processes that I'chiliad detailing in this article. The problem tin come from the data source itself at times and you have to clean it, sometimes it's just your colleague or your manager who requests some specific fields in the final file. Feel costless to share the main issues you've seen from your feel in the comments.
What you need before starting
Python
You'll need the latest Python release: three.7+. I recommend using the Anaconda distribution to get Python, Pandas, and Jupyter. If you already have Anaconda installed, ignore the two following commands.
Seaborn
pip install seaborn Pandas
pip install pandas Jupyter notebook
pip install jupyter Get to piece of work
Let's start with a basic dataset I've institute on Kaggle. This dataset is a search results report for "Flights" and "Tickets" queries searched on Google. When y'all search for a query on Google, the "organic" results volition be ranked in the search result page and simply 10 are listed for each query in this dataset. As you can guess, nosotros might expect duplicates in some fields.
Nosotros volition embrace the following topics:
- Remove useless characters
- Extract relevant content from a Series
- Check NaN values
- Modify the type of your Series
Open up a new Jupyter notebook and import the dataset:
import os
import pandas equally pd df = pd.read_csv('flights_tickets_serp2018-12-sixteen.csv')
We can check quickly how the dataset looks like with the 3 magic functions:
- .info(): Shows the rows count and the types
df.info() 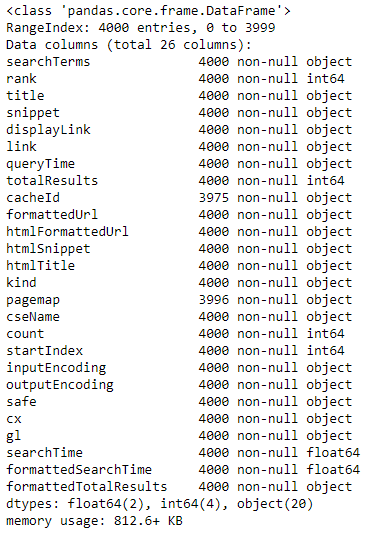
- .describe(): Shows the primary statistics for every numerical column in our dataset
df.describe() 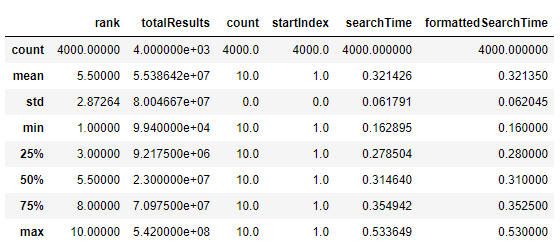
- .caput(): Shows the beginning 5 rows of the dataset (you can change this number by passing an integer as a parameter)
df.head() 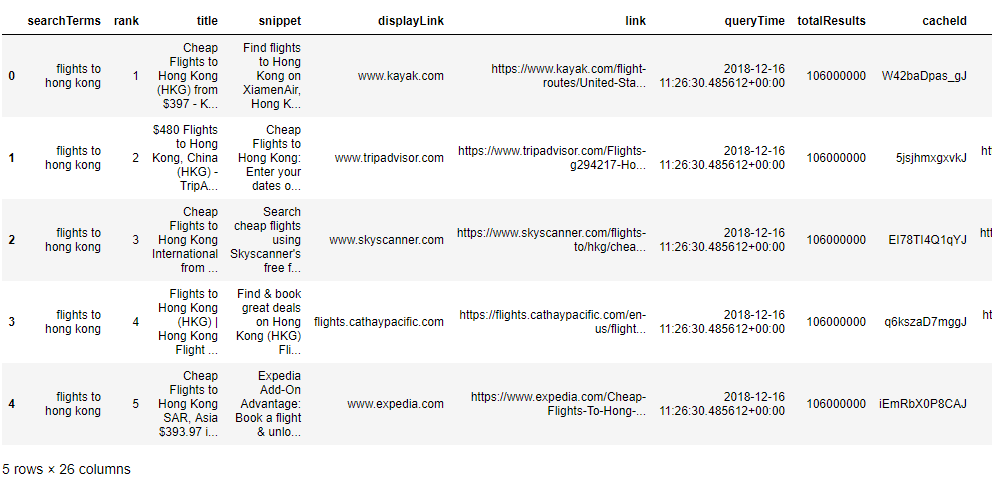
We can even show the cavalcade names considering we have besides many and they don't fit in the screen:
df.columns 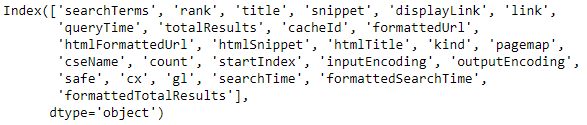
At present we have a better view of what we are dealing with. Starting from this betoken, depending on the context of your company and your objectives, y'all won't be looking for the same thing. Moreover, if this dataset will exist used to feed a Machine Learning algorithm for training or if you need to run an analysis for your manger, your output DataFrame won't look the same. But it'due south non the subject here. Let's continue with the starting time topic.
1. Remove useless characters
Why should nosotros remove characters in a dataset full of information? Well, a dataset is non ever built for your personal utilize-instance but for multiple uses in full general. Again, depending on your project, your focus will exist different.
In the example where you are working on an NLP (=Natural Linguistic communication Processing) project, yous will need to go your text very make clean and get rid of the unusual characters that don't change the significant for instance. If we look closer at the "title" column,
df['title'] 
we can see a few special characters to remove similar: , . ( ) [ ] + | -
If you want to exist safe, you can use a complete list of special characters and remove them using a loop:
spec_chars = ["!",'"',"#","%","&","'","(",")",
"*","+",",","-",".","/",":",";","<",
"=",">","?","@","[","\\","]","^","_",
"`","{","|","}","~","–"] for char in spec_chars:
df['title'] = df['title'].str.replace(char, ' ')
At present you shouldn't have any of those characters in your title column. Because we replaced the special characters with a plus, nosotros might end up with double whitespaces in some titles.
Let's remove them by splitting each title using whitespaces and re-joining the words over again using join.
df['title'] = df['title'].str.split().str.bring together(" ") We're done with this column, we removed the special characters. Note that I didn't include the currencies characters and the dot "." in the special characters listing above. The reason is that some results titles contain the price of the flights tickets they are selling (e.g. "$514.98") and this data might be interesting to extract in the next department.
2. Extract relevant content from a Series
What is of import when y'all work with a dataset is to brand the dataset cleaner, readable. Your dataset might end upwards being ingested in a Machine Learning pipeline, that existence said, the idea is to excerpt a lot of information from this dataset. I'll prove an instance just the granularity of the information you will extract depends on your objectives.
Permit's say yous want to extract all the prices in dollars from the results titles (i.east. the title cavalcade). Nosotros utilize a regex office to exercise that. You can practice some tests with your regex role here if y'all desire.
df['dollar_prices'] = df['title'].str.excerpt('(\$\.d*\.?\d*)') We've now extracted all the prices in dollars in the title column.
Nosotros now display the unique values of the resulting column:
df['dollar_prices'].unique() 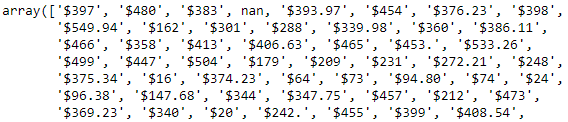
As yous tin encounter and it was expected, nosotros have some NaN (=Not a Number) values (4th position in the array above). Some titles don't accept a dollar cost so the regex dominion couldn't notice it, instead, nosotros have "nan". We'll see in the side by side section how to deal with the NaN values.
3. Check NaN values
Most of the time, a big dataset volition contain NaN values. What to do with them? Should we leave them? Admittedly not! You tin't leave them considering of the calculations you might perform on numerical columns or just because of time to come modeling a Data Science team or even you could practice. For those who know about Machine Learning, more or less, you know that your features/variables/predictors should exist numerical before grooming a model. For all these reasons, we want to gear up the NaN values. I won't spend too much time dealing with the different strategies, at that place are plenty of articles explaining different strategies. What you can do:
- Remove the corresponding rows: This can be done only if removing the rows doesn't affect the distributions in your dataset or if they are not significant. If at that place are just 3 rows with some NaN values in your 1M dataset, information technology should be safe to remove the rows. Otherwise, you might have to go with the next options.
- Utilize statistics to replace them (in numerical columns): Yous can replace the NaN values by the mean of the cavalcade. Be careful, you don't want to skew the data. It might exist more than relevant to look at another column like a chiselled one and supercede the NaN values based on the hateful for each category. Let me explain. In the Titanic dataset, for case, each row represents a rider. Some values in the Fares column are missing (NaN). In gild to replace these NaN with a more than authentic value, closer to the reality: you tin can, for example, replace them by the hateful of the Fares of the rows for the same ticket type. You assume by doing this that people who bought the same ticket type paid roughly the aforementioned price, which makes sense.
- Else: Try to know well your domain, your context which will help yous to know how to replace in a safety way the missing variables. If you won't utilise this dataset in a Motorcar Learning pipeline, you tin can replace the NaN with some other value like a cord (in case of a string blazon cavalcade) "None" or "NoData", annihilation relevant for y'all and the people who will use the dataset.
For more than examples about dealing with the NaN values, I recommend reading an article with a focus on that particular point.
Almost our dataset, let's see what is the proportion of NaN values using a visualization library chosen seaborn. You lot can do it with Pandas functions directly simply I think it'south skillful to go starting time with a visual fashion so you go to know your data:
sns.heatmap(df.isnull(), cmap='viridis') 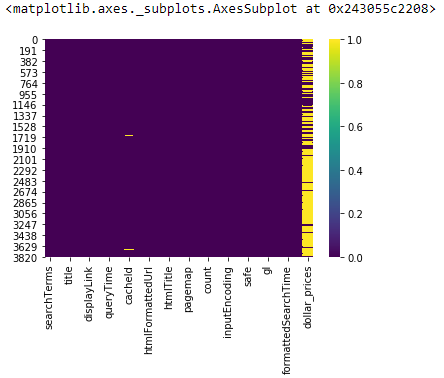
In this heatmap, you can see in yellow (depending on the cmap you are using, just with mine it'south yellowish) the NaN values in each cavalcade. It doesn't mean that a column with no yellow doesn't take whatever NaN, it happens to take some at the top of the heatmap or at the bottom so they are confused with the graphical borders of the heatmap (it's due to the resolution of the image printed in the notebook). Anyway, don't hesitate to prove the raw data using the .isnull() Pandas function.
In our example, we will just keep the rows where we have a dollar_price in the title so nosotros will just keep the rows with a value in the dollar_price column:
df = df.dropna(subset=['dollar_prices']) The resulting DataFrame contains only the rows where dollar_price has a value, the others take been dropped.
4. Change the type of your Series
In this dataset, we might not take a lot of type changes to do. It depends on your context and the quality of the dataset. If you're happy with the column types every bit we saw with df.info(), that'due south fine.
The input file might come from a colleague of yours who saved the data into an Excel file (.xlsx). In that case, and that'south because Excel is terrible for this, the format of your columns could be inverse particularly for your Ids columns. By "Ids" I hateful a column that represents an Id for 1 of your listed entities. For case, if you're manipulating a dataset containing an inventory of products, you'll probably accept a ProductId column in it. Anyway, numerical Ids in Excel tin can be interpreted as a numerical column or text cavalcade and to exist honest with you I don't know when Excel chooses 1 or the other.
For your information manipulation, it depends on how yous want to treat Ids in your script, exercise you desire to manipulate text (string) or numerical values (integer)? That's upwardly to y'all, simply be consequent in your script, if you need to join ii DataFrames, based on an Id cavalcade, for case, convert them first in the same format (cord or integer but you have to choose i).
Permit's become back to our dataset. In the second section, we created a new column containing the prices in dollars. At this indicate, we know in that location are in dollars, right? Because this information well-nigh the currency is in the column name. That being said, we can get rid of the dollar characters:
df['dollar_prices'] = df['dollar_prices'].str.supersede('$', '') The last step is to check the type of this column. We should accept a cord as we extracted the data with the regex rule every bit strings:
df.dtypes 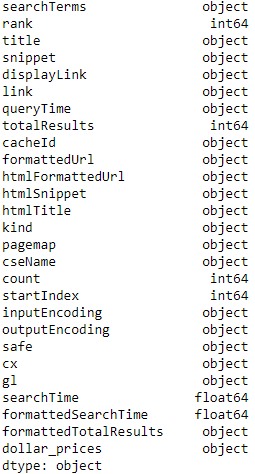
Here our dollar_prices is an object that means a string actually. Do we really want to consider our prices equally strings? We will prefer to use floats for the prices, we just need to catechumen the column blazon.
df['dollar_prices'] = pd.to_numeric(df['dollar_prices'], errors='coerce') If you bear witness the dtypes i more time, you'll detect that the dollar_prices column is no longer an object only it's now a float64 type.
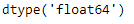
Conclusion
I hope you lot found some answers to the questions you might have asked yourself. Every bit I said in the beginning, there is no universal manner to clean a dataset, some checks take to exist washed like the NaN values for example. The rest really depends on what level of quality do you lot demand for the projection? What data are relevant to extract?
Also, go along in heed that everything you can excerpt from your dataset (section ii) might be really helpful for visualization specialists who volition build dashboards using your dataset as a source.
The Jupyter notebook is available in my GitHub merely hither.
Don't hesitate to write comments and questions.
yimhatemselithe1943.blogspot.com
Source: https://towardsdatascience.com/simplify-your-dataset-cleaning-with-pandas-75951b23568e
0 Response to "How to Read a Text File Seaborn"
Post a Comment